Oh, the Places You'll Go! Finding Our Way Back from the Web Platform's
Ill-conceived Jaunts
[...]
Abstract
In its transition from the original concept of a mesh of hypertext
documents into the world's most successful application ecosystem, the
open web platform has steadily, iteratively, accumulated a large
number of unsafe features and behaviors. These features lead to
vulnerabilities in web applications, enable attacks on web users, and
often add significant complexity to developers' mental models of the
web and to user-agent implementations.
In this paper, we start from a scattered list of concrete grievances
about the web platform based on informal discussions among browser-
and web security engineers. After reviewing the details of these
issues, we work towards a model of the root causes of the problems,
categorizing them based on the type of risk they introduce to the
platform. We then identify possible solutions for each class of
issues, dividing them by the most effective approach to address it.
In the end, we arrive at a general blueprint for backing out of these
dead ends. We propose a three-pronged approach which includes
changing web browser defaults, creating a slew of features for web
authors to opt out of dangerous behaviors, and adding new security
primitives. We then show how this approach can be practically applied
to address each of the individual problems, providing a conceptual
framework for solving unsafe legacy web platform behaviors
– A. Janc, M. West
Information Leaks via Safari's Intelligent Tracking Prevention
[...]
Abstract
Intelligent Tracking Prevention (ITP) is a privacy mechanism
implemented by Apple's Safari browser, released in October 2017. ITP
aims to reduce the cross-site tracking of web users by limiting the
capabilities of cookies and other website data.
As part of a routine security review, the Information Security
Engineering team at Google has identified multiple security and
privacy issues in Safari's ITP design. These issues have a number of
unexpected consequences, including the disclosure of the user's web
browsing habits, allowing persistent cross-site tracking, and
enabling cross-site information leaks (including cross-site search).
This report is a modestly expanded version of our original
vulnerability submission to Apple (WebKit bug #201319), providing
additional context and edited for clarity. A number of the issues
discussed here have been addressed in Safari 13.0.4 and iOS 13.3,
released in December 2019.
– A. Janc, L. Weichselbaum, K. Kotowicz, R. Clapis
⌖ Google Research, 2020
[
PDF]
CSP is dead, long live CSP! On the insecurity of whitelists and the
future of Content Security Policy.
[...]
Abstract
Content Security Policy is a web platform mechanism designed to
mitigate cross-site scripting (XSS), the top security vulnerability
in modern web applications. In this paper, we take a closer look at
the practical benefits of adopting CSP and identify significant flaws
in real-world deployments that result in bypasses in 94.72% of all
distinct policies.
We base our Internet-wide analysis on a search engine corpus of
approximately 100 billion pages from over 1 billion hostnames; the
result covers CSP deployments on 1,680,867 hosts with 26,011 unique
CSP policies — the most comprehensive study to date. We
introduce the security-relevant aspects of the CSP specification and
provide an in-depth analysis of its threat model, focusing on XSS
protections. We identify three common classes of CSP bypasses and
explain how they subvert the security of a policy.
We then turn to a quantitative analysis of policies deployed on the
Internet in order to understand their security benefits. We observe
that 14 out of the 15 domains most commonly whitelisted for loading
scripts contain unsafe endpoints; as a consequence, 75.81% of
distinct policies use script whitelists that allow attackers to
bypass CSP. In total, we find that 94.68% of policies that attempt to
limit script execution are ineffective, and that 99.34% of hosts
with CSP use policies that offer no benefit against XSS.
Finally, we propose the 'strict-dynamic' keyword, an
addition to the specification that facilitates the creation of
policies based on cryptographic nonces, without relying on
domain whitelists. We discuss our experience deploying such
a nonce-based policy in a complex application and provide
guidance to web authors for improving their policies.
– L. Weichselbaum, M. Spagnuolo, S. Lekies, A. Janc
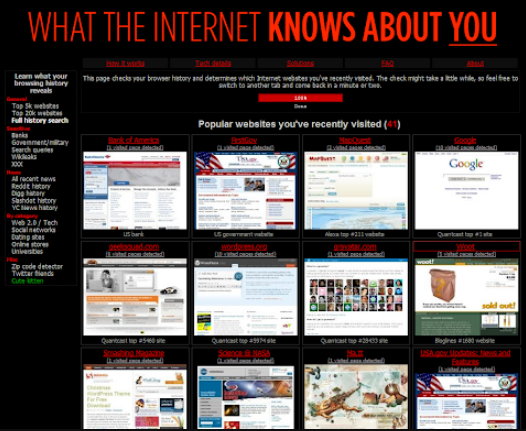
Why Johnny can't browse in peace: On the uniqueness of web browsing
history patterns.
[...]
Abstract
We present the results of the first large-scale study of the
uniqueness of Web browsing histories, gathered from a total of 368,284
Internet users who visited a history detection demonstration
website.
Our results show that for a majority of users (69%), the
browsing history is unique and that users for whom we could detect at
least 4 visited websites were uniquely identified by their histories
in 97% of cases. We observe a significant rate of stability in
browser history fingerprints: for repeat visitors, 38% of
fingerprints are identical over time, and differing ones were
correlated with original history contents, indicating static browsing
preferences (for history subvectors of size 50). We report a striking
result that it is enough to test for a small number of pages in order
to both enumerate users' interests and perform an efficient and
unique behavioral fingerprint; we show that testing 50 web pages is
enough to fingerprint 42% of users in our database, increasing to 70%
with 500 web pages.
Finally, we show that indirect history data, such as information
about categories of visited websites can also be effective in
fingerprinting users, and that similar fingerprinting can be
performed by common script providers such as Google or Facebook.
– L. Olejnik, C. Castelluccia, A. Janc
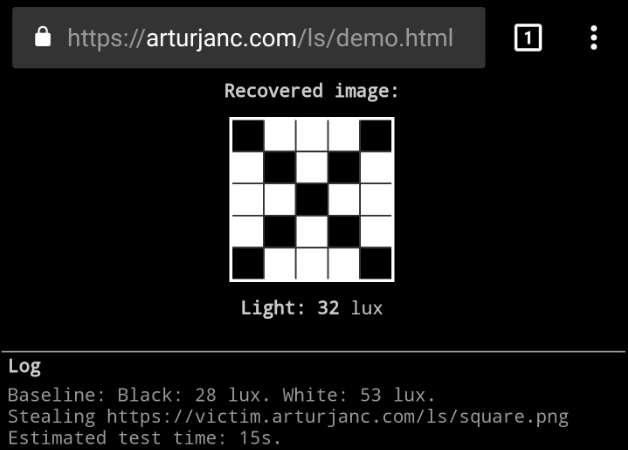
Feasibility and real-world implications of web browser history
detection
[...]
Abstract
Browser history detection through the Cascading Style Sheets visited
pseudoclass has long been known to the academic security community
and browser vendors, but has been largely dismissed as an issue of
marginal impact.
In this paper we present several crucial real-world considerations of
CSS-based history detection to assess the feasibility of conducting
such attacks in the wild. We analyze Web browser behavior and
detectability of content returned via various protocols and HTTP
response codes. We develop an algorithm for efficient examination of
large link sets and evaluate its performance in modern browsers.
Compared to existing methods our approach is up to 6 times faster,
and is able to detect as many as 30,000 links per second in recent
browsers on modern consumer-grade hardware.
We present a web-based system capable of effectively detecting
clients' browsing histories and categorizing detected
information. We analyze and discuss real-world results obtained from
271,576 Internet users. Our results indicate that at least 76% of
Internet users are vulnerable to history detection; for a test of
most popular Internet websites we were able to detect, on average, 62
visited locations. We also demonstrate the potential for detecting
private data such as zipcodes or search queries typed into online
forms. Our results confirm the feasibility of conducting attacks on
user privacy using CSS-based history detection and demonstrate that
such attacks are realizable with minimal resources.
– A. Janc, L. Olejnik




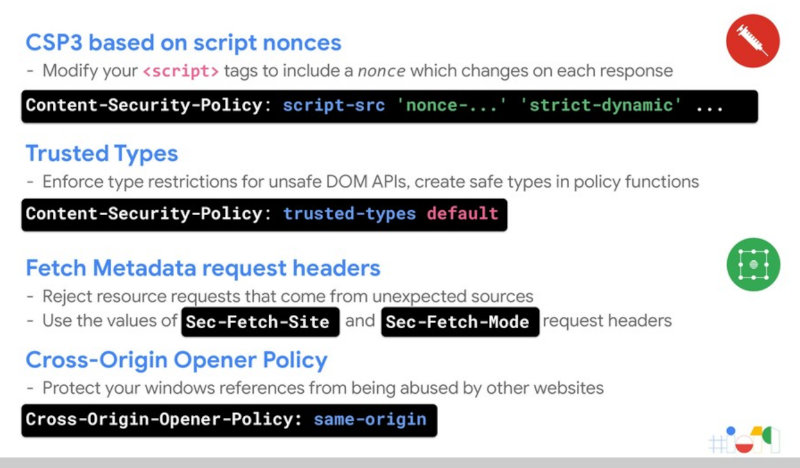 If you prefer your information in video form, you can
If you prefer your information in video form, you can